刚刚,豆包2.1发布!Agent自己跑18个小时搞定芯片设计代码
金磊 发自 凹非寺
量子位 | 公众号 QbitAI
就在刚刚,又一个新版国产模型来了。
这次的主角是字节——Seed 2.1系列。

△火山引擎总裁,谭待
这个版本一共包含2个模型,分别是Doubao-Seed-2.1-Pro和Doubao-Seed-2.1-Turbo,并且API服务已全量上线火山方舟。
那么这个新模型到底什么水平?
火山引擎便放出了一个很直观且有feel的案例:
视频演示的是芯片设计行业里非常严谨的RTL环节,会细节到每个寄存器和信号线在每个时钟周期里怎么流动都得说清楚。
这个工作量基本上得3-5名人类工程师花数周时间才能搞定。
而Seed 2.1 Pro围绕一个16×16 PE的Tiny NPU Tile,连续运行近18个小时,经历9轮迭代,最终完成了6个核心模块、1303行RTL代码!
再来看下榜单评分的表现。
以贴近真实终端编程环境的Terminal Bench 2.1为例,Seed 2.1 Pro已经做到了基本上能和Claude Opus 4.7持平;在科学计算代码评测SciCode上,Seed 2.1 Pro甚至超过Opus 4.7和GPT-5.5。

并且像工具调用的MCP-Atlas评测,Seed 2.1 Pro同样是超过了Opus 4.7和GPT-5.5。
在六月新鲜出炉的Agents’ Last Exam(ALE,覆盖13个行业集群、1000多项高经济价值真实任务)基准评测中,Seed 2.1 Pro已经处于当前参评模型的第一梯队水平。

还有一个非常实在的亮点,那就是价格。
因为Seed 2.1 Pro在能力跟国外头部AI做到比肩的同时,价格还仅仅是1/4(以Opus 4.6-4.8为例):
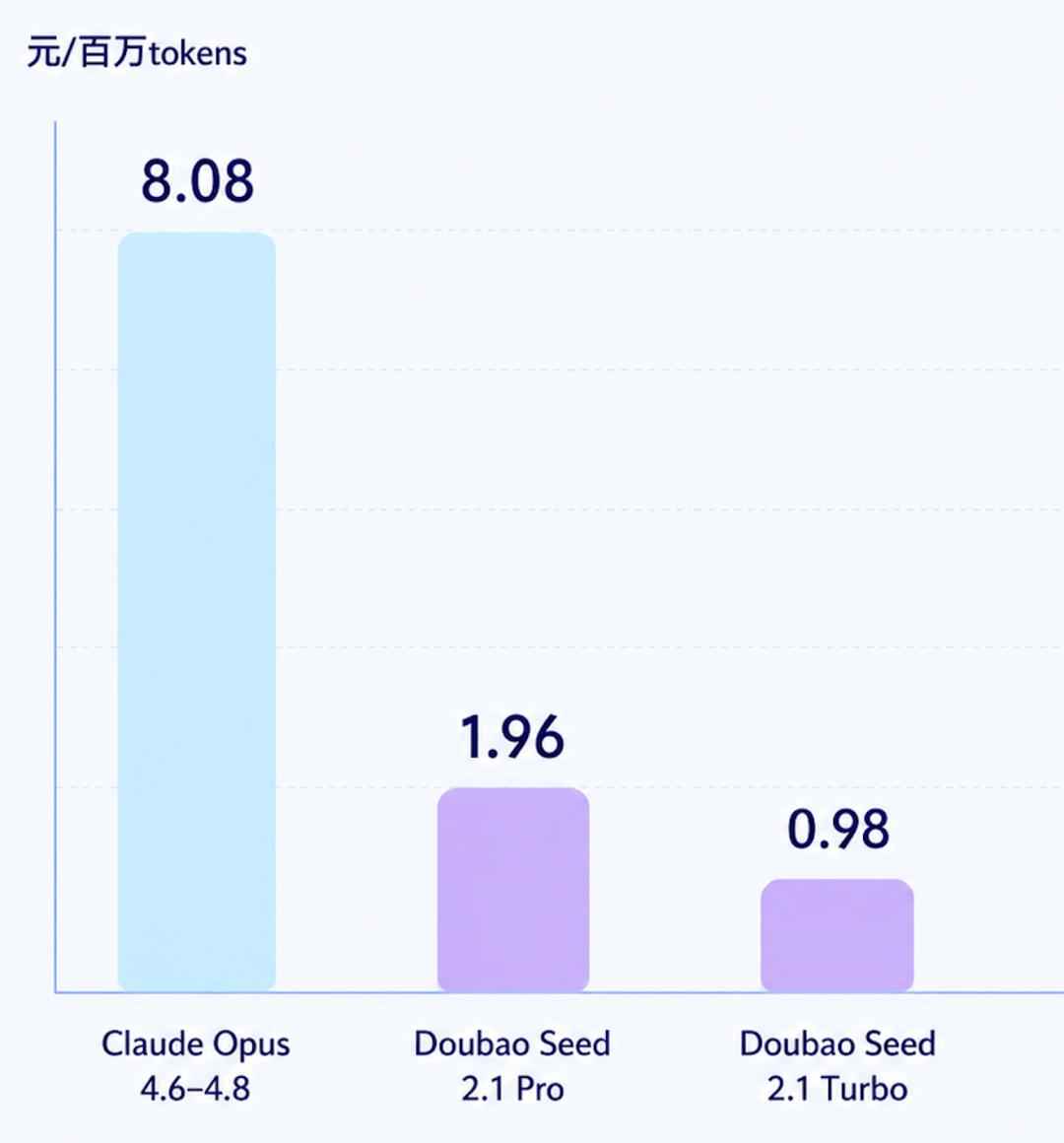
并且放眼国内玩家,Seed 2.1 Pro也是具备一定优势:
每百万Token输入价格为6元、输出价格为30元、缓存命中条件下只需要1.2元。
并且根据火山引擎总裁谭待的介绍,豆包日均Token的使用量已经突破180万亿!

那么把豆包最新模型丢到实实在在的工作环境,它的效果到底如何?
老规矩,一波实测走起~
把Seed 2.1 Pro扔进一天的工作流
先说下测试环境。
我们这次主要在OpenCode中调用Seed 2.1 Pro API完成。
也就是把它放进一个更接近Claude Code、Codex的开发者环境里,看它面对长Prompt、代码生成、文件型交付和结构化报告时,能不能真正把任务跑下来。
第一个任务,我们直接上强度:
生成一个完整的3D房屋
我们给Seed 2.1 Pro的Prompt是这样的:
这类任务有意思的地方在于,它同时测了几件事:
模型能不能理解复杂需求,能不能把3D图形拆成可执行的几何结构,能不能在没有外部库的情况下,把WebGL渲染、相机控制、光照、材质、交互都写出来,以及能不能在OpenCode里根据结果继续迭代。
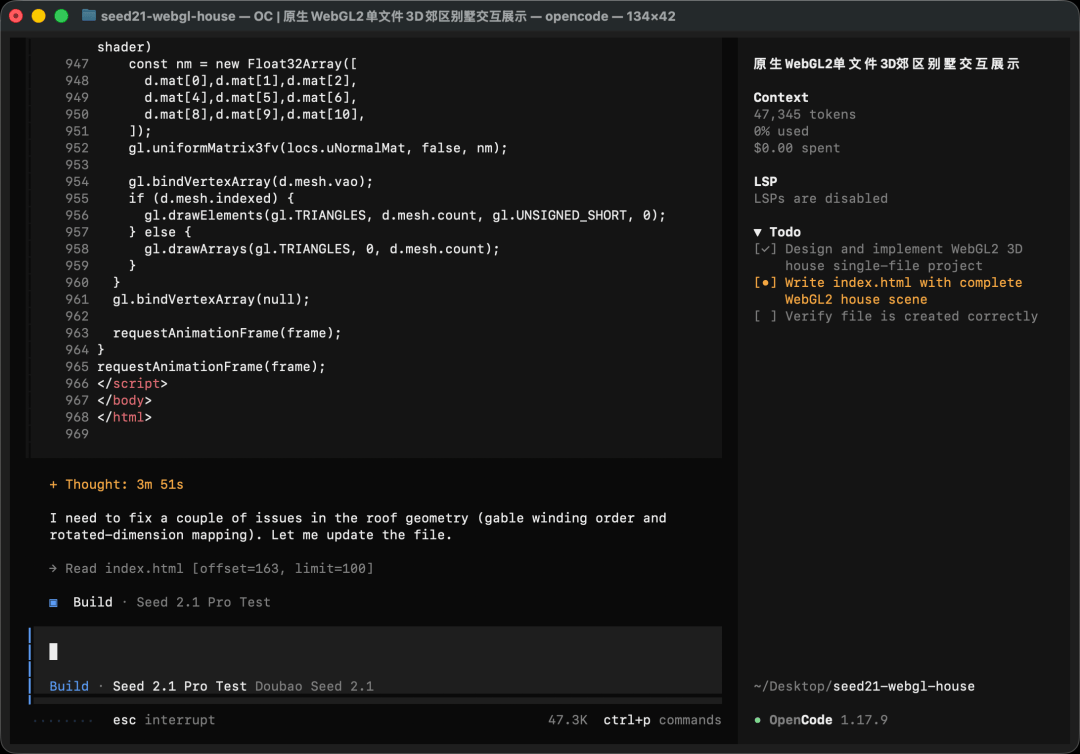
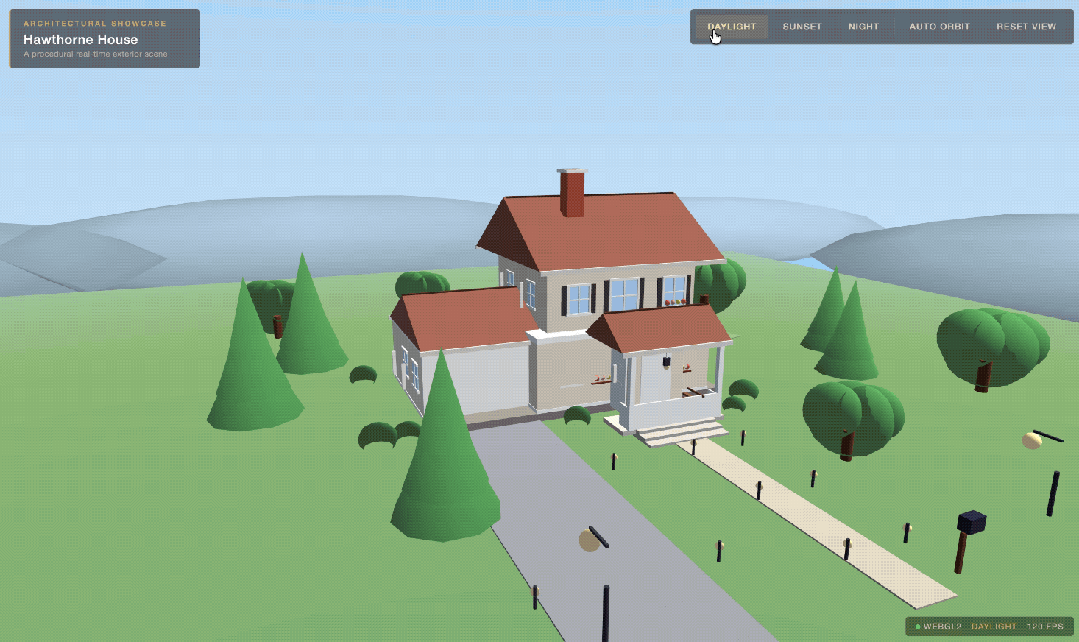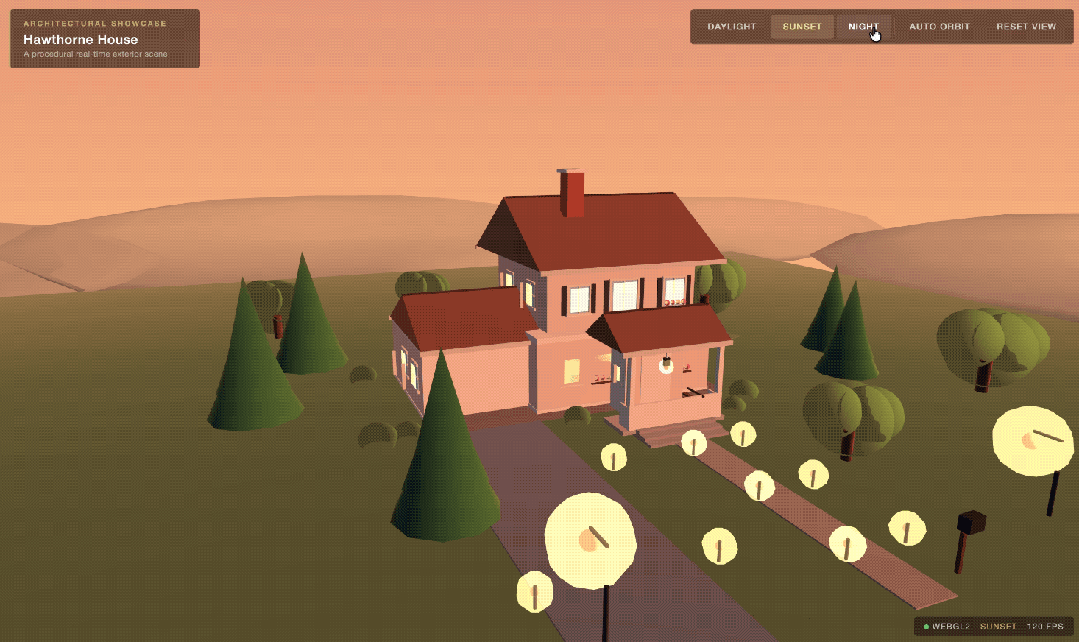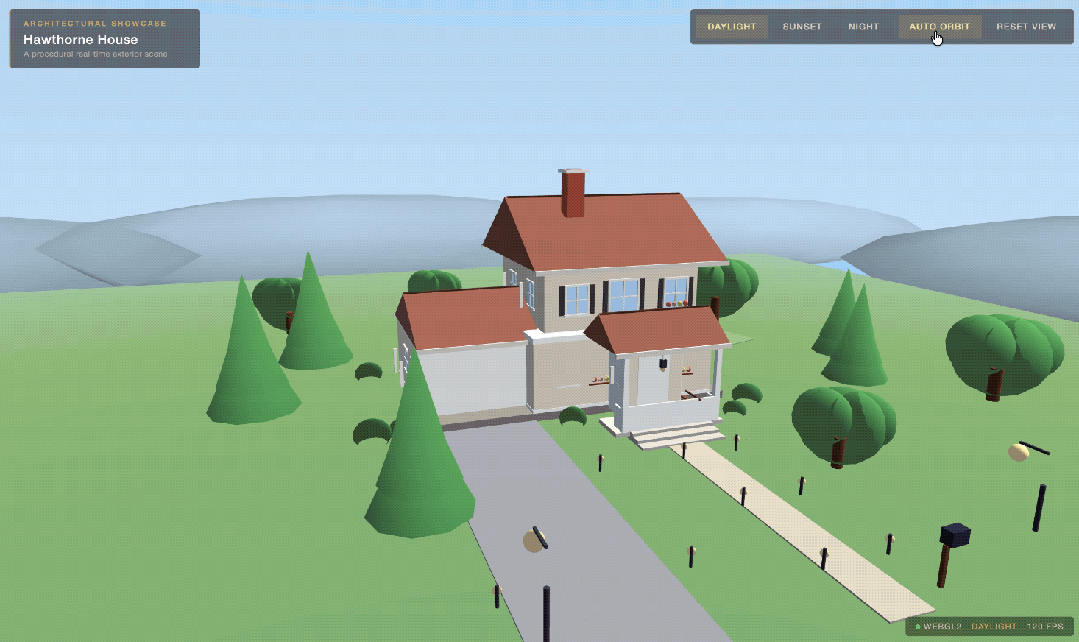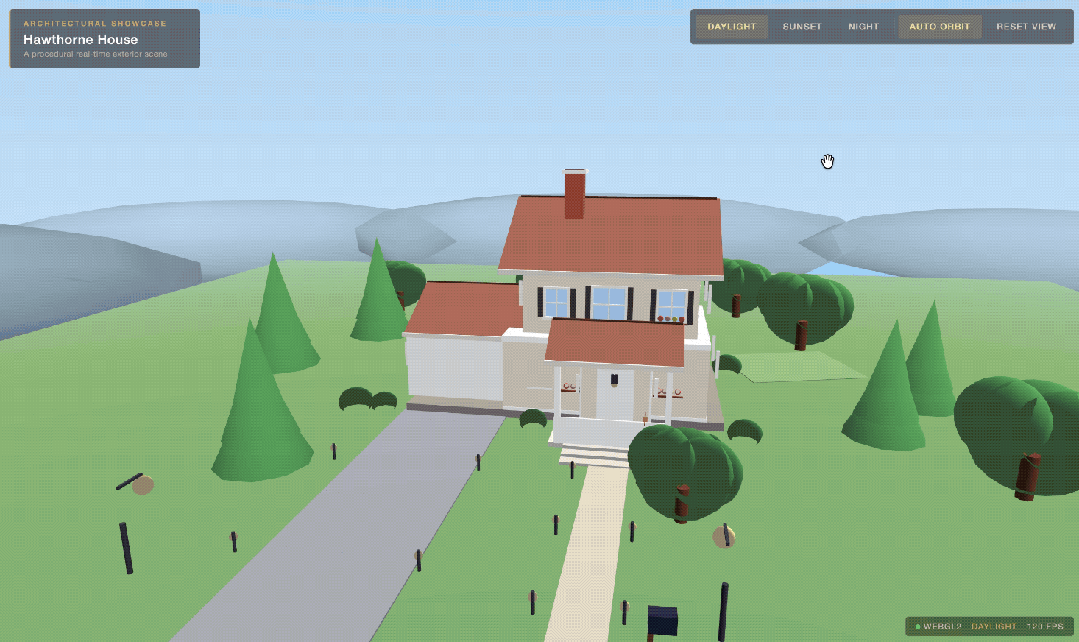
在稍等片刻过后,一个3D房屋就诞生了:

但有一说一,第一版的效果还是比较简陋,因此我们在上一轮的基础上,继续做优化。
我们再给到Seed 2.1 Pro这样的Prompt:
在优化的过程中,我们不难发现,Seed 2.1 Pro不会只一次性地去生成代码,它会有一个逐行代码再检查的过程:
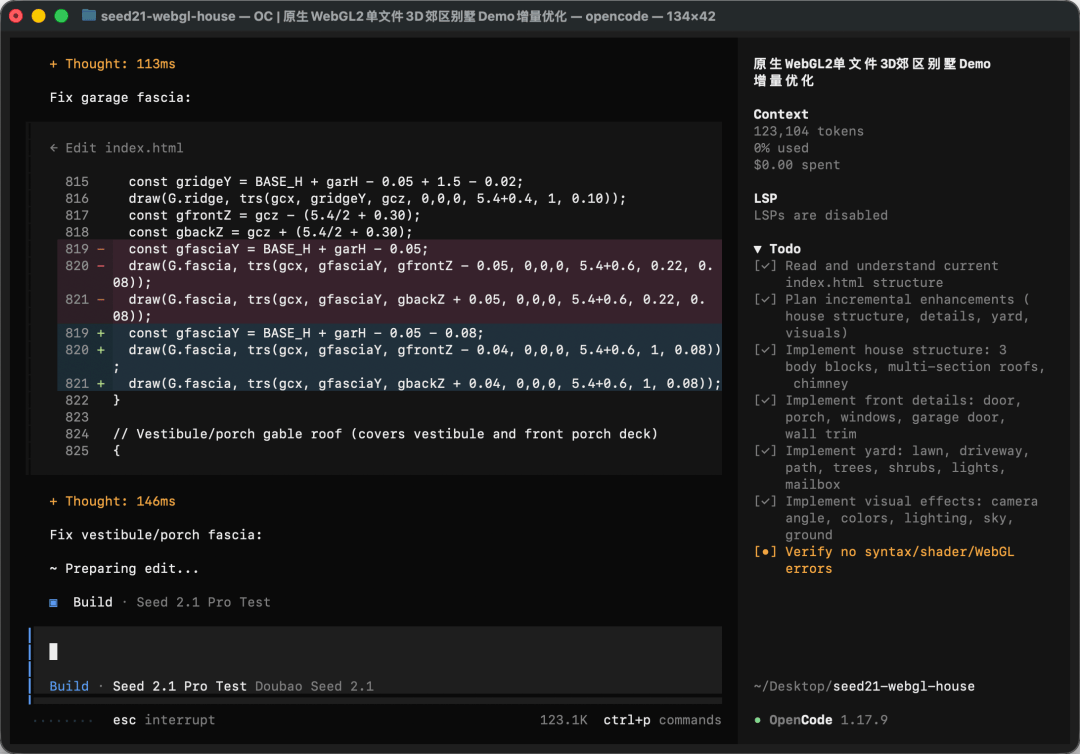
在第二轮优化之后,3D房屋的效果就变成了这样:

在经过一次优化迭代之后,3D房屋的效果要比第一次更加柔和且细粒度了一些。
以此类推,再经过Seed Pro 2.1一次优化迭代之后(提出更加细节的Prompt),我们便得到了最终的成品:
直接生成一个可用的PPT
虽然这个任务看着像在用开发者工具里做PPT,但这也刚好能体现同一个API既能搞开发,也能做汇报工作。
然后这次我们给Seed 2.1 Pro的Prompt是这样的:
同样的,Seed 2.1 Pro依旧是在分析完任务需求之后,给自己制定了Todo list,然后按照计划一步一步地执行:
在片刻过后,刚才我们Prompt里提到的所有文件,就这么水灵灵地一口气诞生了:
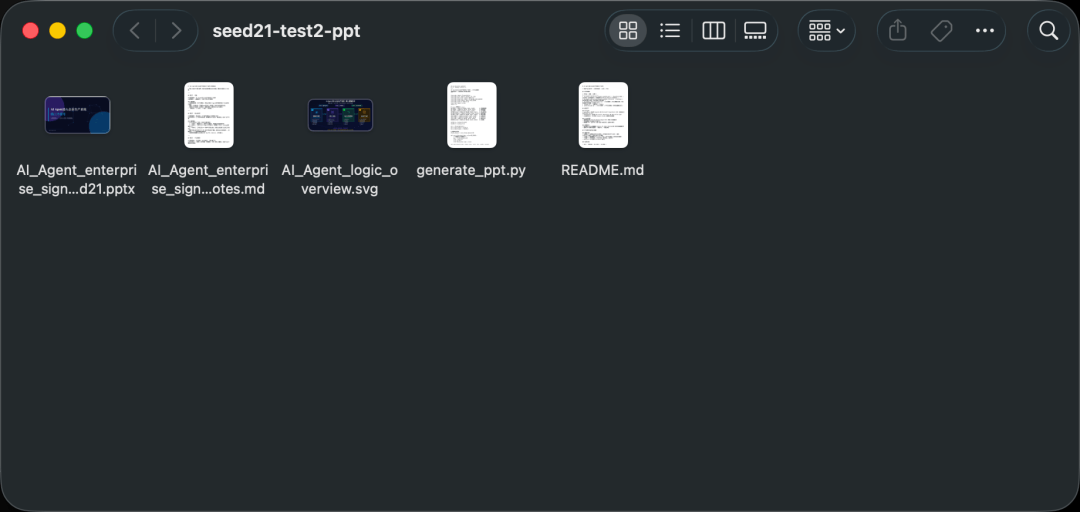
我们先来看下PPT的效果:

和以往AI做PPT感触很不一样的一点是,这次不论是内容,还是设计感,已经没有那种一眼AI的感觉。
相反的,Seed 2.1 Pro做出来的PPT,真的是可以直接拿来用了。
当然,SVG图也是不在话下的。

一张乱表,秒做数据分析
这类任务表面上是算数,实际上测的是三件事,也就是表格理解、异常识别、业务解释。
我们的Prompt如下:
和做PPT类似,Seed 2.1 Pro在运行完自己制定的Todo list后,甩出了一份生成的文件清单:
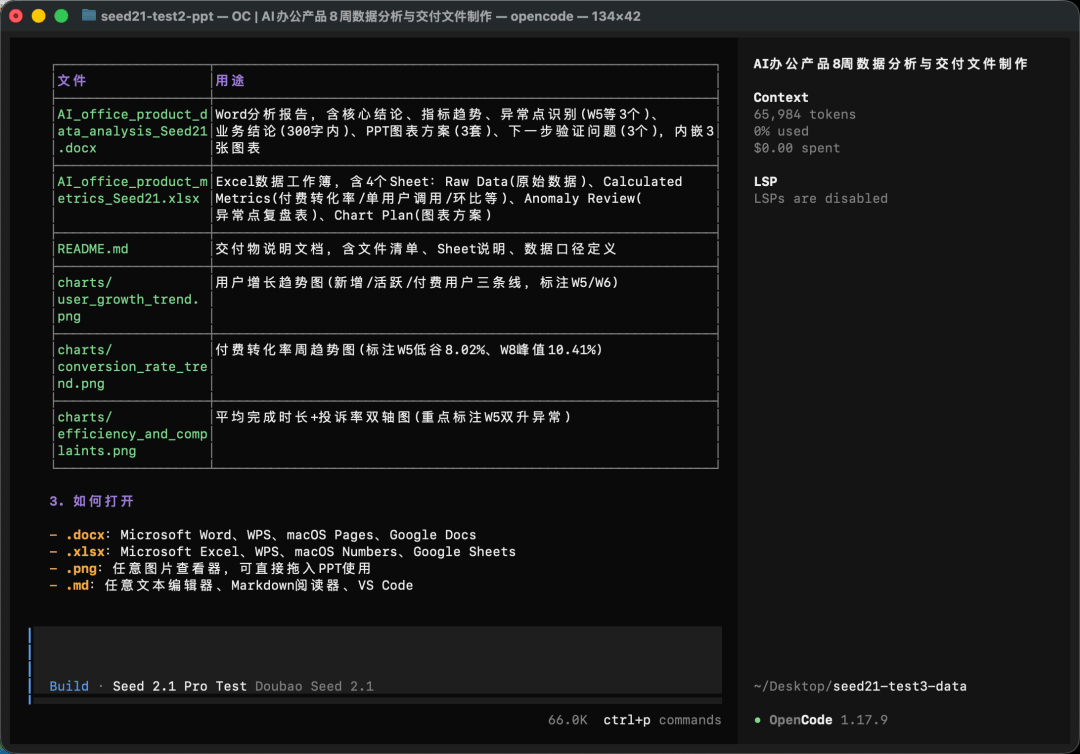
生成的Word分析报告,是带好排版、有图表分析的:

数据是在Excel被整理好的:
方便,着实是方便。
以后这种需要各种格式、各种模态一起输出的工作,真的可以放心交给AI了。
截图直接变PRD
除了用Seed 2.1 Pro的API来实测之外,我们还提前拿到了豆包办公任务模式的内测资格。
据说这个模式背后的模型,正是Seed 2.1 Pro:
经实测,我们发现刚才用API能做的事情,办公任务模式也是基本都能hold住。
例如Coding能力,就可以直接做一个任务指挥塔:

做出来的PPT甚至是自带备注的:

而整体实测下来,用豆包APP上的办公任务模式比较方便的一点,就是传文件,直接鼠标拖拽一下就好。
例如我们直接在网页中截取一个界面:
这就比较考验Seed 2.1 Pro的视觉理解、多模态推理和产品化表达能力了。Prompt是这样的:
从体感上来看,在豆包办公任务模式里,它更像一个面向普通用户的办公Agent:
不用配环境,不用写代码,上传截图、输入任务,就能拿到一份可继续修改的PRD草稿。
这两种入口对应的用户完全不同,但也正如我们刚才提到的,背后用的都是Seed 2.1 Pro。
更关键的是,Seed 2.1 Pro不是只服务豆包一个入口。
据悉,它已经同步进入TRAE、TRAE WORK、扣子等字节系产品。
也就是说,同一个基座模型,一头连API和开发者,一头连TRAE这样的AI Coding工具,一头还将连豆包办公入口。
颇有一种一个大招打通任督二脉的感觉了。
不只是又发了个新模型
现在回头看Seed 2.1 Pro,它的核心变化,不只是模型分数又涨了。
过去国产基模的竞争,很多时候还停留在“聊天能力追没追上”“榜单分数高不高”。但Agent时代,用户更关心任务完成率:模型能不能连续理解上下文,能不能拆任务、执行任务、生成文件、看图、写代码,并且在关键节点知道交给人确认。
这也是为什么“生产级可用”会成为这轮模型升级的关键词。
生产级可用,不代表模型永远不出错,而是它的输出可以进入真实工作流,错误也能被发现、修改和追责。
从这个角度看,Seed 2.1 Pro这次的能力提升,和字节的产品入口结合在一起,意义会更大。
火山方舟面向开发者和企业API调用,豆包专业版承接办公生产力,TRAE和TRAE WORK切进AI Coding,扣子负责Agent应用搭建。同一个模型底座,覆盖了个人办公、开发者工具和企业Agent应用几条关键路径。
这和单纯发布一个模型很不一样。
模型能力本身会被追赶,真正难的是把模型放进高频场景里,让用户每天打开、每天调用、每天产生新的反馈。字节的优势,也正在这里。
它有C端豆包,有开发者工具TRAE,有Agent搭建平台扣子,还有火山方舟这样的企业级API入口。Seed 2.1 Pro如果能在这些入口里持续提升任务完成质量,它争夺的就不只是模型榜单,还有Agent时代的生产入口。
当然,也要客观看。
从这次实测看,Seed 2.1 Pro已经能在API和产品入口两端产出相当完整的工作底稿,但还不能完全脱离人工审核。数据分析会出现细节不一致,PPT里的行业数据需要核验,代码项目离生产系统还有工程距离,截图PRD也无法替代真实用户研究。
所以它现在最适合的位置,是“第一生产力助手”:先把70%的粗活干完,再让人做最后30%的判断、校验和润色。
这已经足够改变很多工作流。
以前做PPT,要查资料、搭框架、画结构图、写讲稿。现在可以先让Seed 2.1 Pro出第一版,人再去校事实、调观点、改表达。
以前做3D项目,要搭环境、写渲染管线、拆几何体、调交互。现在可以先让它生成一个可跑版本,人再继续补工程细节和视觉质感。
以前做行业研究,要先把资料整理成表,再提炼判断。现在它已经能把表格、判断、风险提示一次性给出来。
OpenCode里的测试说明,它已经能进入更专业的开发者工作流;豆包办公任务模式里的测试,则说明它也在向普通办公人群靠近。
前者考验模型执行力和长程任务稳定性,后者考验产品体验和任务封装能力。一个模型要真正走向生产级可用,这两件事缺一不可。
过去我们测国产模型,常见问题是它会不会聊、分数高不高、有没有追上Claude。
不过讲点实在的,榜单还仅是入场券,工作流才是主战场。
Seed 2.1 Pro这次要证明的,也正是这件事。
One More Thing:
火爆全球的视频生成模型Seedance,这次也是升级到了2.5版本(仍在测试中,预计将在 7 月初正式上线)。
这一次,Seedance 2.5可以单次直出30秒视频,并且在长视频连贯性、复杂镜头控制和画质方面较上一版本有明显提升。
Seed 2.1 API接入地址:
[1]https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-2-1-pro
[2]https://console.volcengine.com/ark/region:ark+cn-beijing/model/detail?Id=doubao-seed-2-1-turbo