DeepSeek V3.2爆火,Agentic性能暴涨40%解密

新智元报道
编辑:艾伦
【新智元导读】DeepSeek V3.2的Agentic能力大增,离不开这项关键机制:Interleaved Thinking(交错思维链)。Interleaved Thinking风靡开源社区背后,离不开另一家中国公司的推动。
大模型的「健忘症」,早该治治了!
当你试图用当今最先进的大模型帮你完成一个复杂的长假规划,比如「带全家老小去云南玩七天」时,往往很可能会遭遇一个令人崩溃的时刻:
起初,这位「导游」表现得极其靠谱,分析得头头是道。
它记得你说的每一句要求,帮你规划了昆明到大理的路线,甚至贴心地避开了游客太多的网红店。
但随着对话进行到第十轮,你们为了选酒店修改了五次方案,又为了某顿晚餐争论了半天后,它突然「失智」了。
它开始忘记你一开始强调了无数遍的死命令:「带着80岁的奶奶,绝对不能安排爬山和剧烈运动」。
在最新的行程表里,它竟然兴致勃勃地建议:「第四天清晨:全家早起徒步攀登玉龙雪山,欣赏日照金山,全程耗时4小时……」

图片由Nano Banana Pro生成
在AI工程界,这种现象有一个术语:状态漂移(State Drift)。
这并非模型「变笨」了,而是我们让它思考的方式错了。
为了治愈这种「健忘症」,Anthropic Claude、OpenAI GPT-OSS、MiniMax M2、Kimi K2 Thinking等国内外各大模型都不约而同地选择了同一项技术:一边思考,一边用工具(Thinking in Tool-Use)。
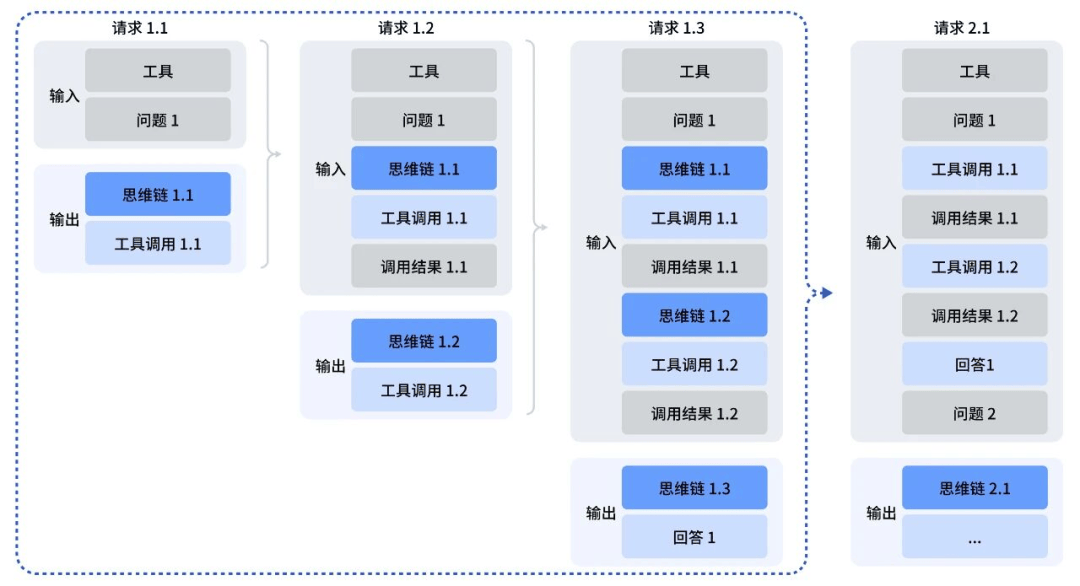
DeepSeek: Thinking in Tool-Use
MiniMax等部分厂商也将其称作Interleaved Thinking(交错思维链),从示意图即可看出,二者本质上是等价的。这是一个更贴近技术的称呼。
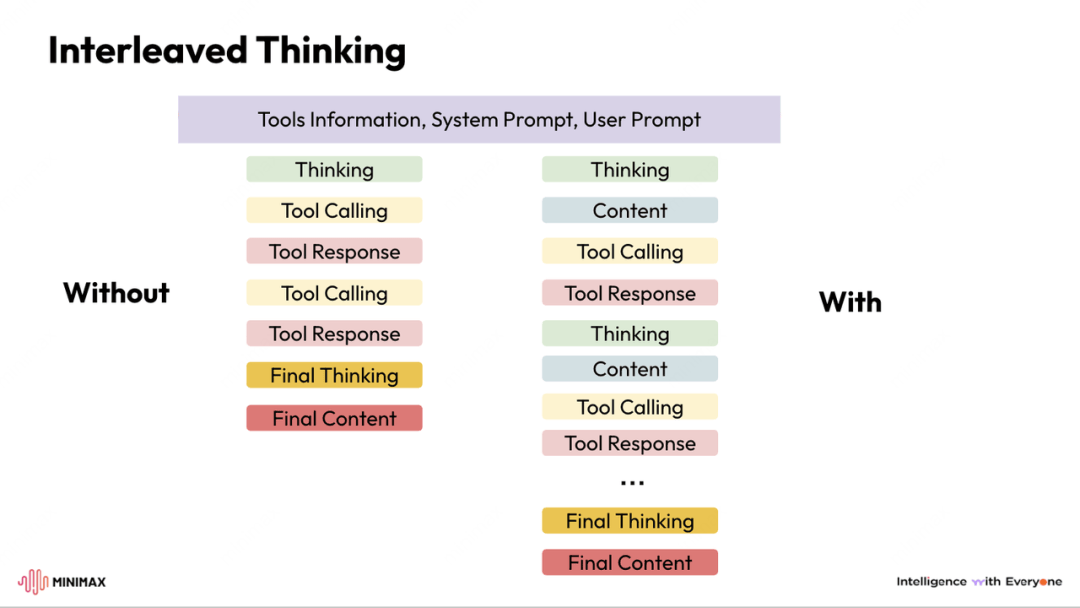
Minimax: Interleaved Thinking(交错思维链)
如图所示,交错思维链即模型在推理(thinking)和工具调用(action)之间来回交替,并持续保留和复用每一轮的推理状态,从而实现稳定、可累积的长程规划。
崩溃的ReAct
与「隐式推理」的诅咒
要理解交错思维链为什么是「神技」,我们得先看看它的前任——早期的ReAct(Reasoning+Acting)范式是如何遇到瓶颈的。
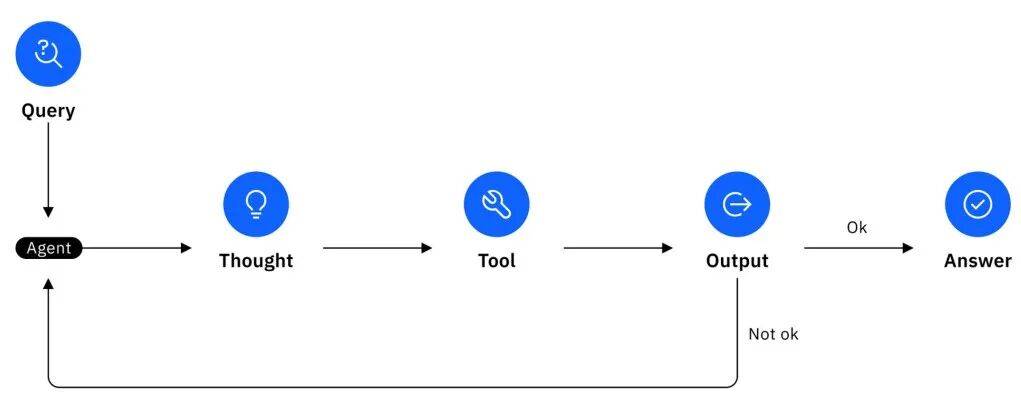
ReAct流程示意图
在很长一段时间里,我们构建AI Agent的逻辑非常线性:观察->思考->行动。
这看起来很符合直觉,但在实际的工程实现(如OpenAI的Function Calling(函数调用))中,这个过程往往被简化成了「模型直接输出工具调用指令」。
问题就出在这里。
模型在输出Action(比如「读取文件A」)的那一刻,它的「脑子」是清醒的。
但当工具执行完毕,返回了数千行的代码或网页内容后,模型进入下一轮生成时,它面临着巨大的环境扰动。
想象一下,你是一个程序员,每写一行代码,就有人把你打晕,清除你的短期记忆,然后把刚才的运行日志扔给你,让你继续写。
由于缺乏显式的、连续的思维记录,模型很容易被复杂的工具返回结果带偏。
它可能会被报错信息吸引注意力,从而忘记了原本的长期规划。
这就是「隐式推理」的诅咒。
模型的思考过程隐藏在权重里,一旦被打断(Turn-based interaction),这些思维火花就烟消云散了。
交错思维链:给Agent装上「海马体」
MiniMax的研发团队在开发M2模型时,敏锐地捕捉到了这个痛点。
Agent需要的不只是更长的上下文窗口,更是一种显式的、可累积的思考状态。
这就是交错思维链。
它的工作流变成了:思考->行动->观察->思考->行动->观察...
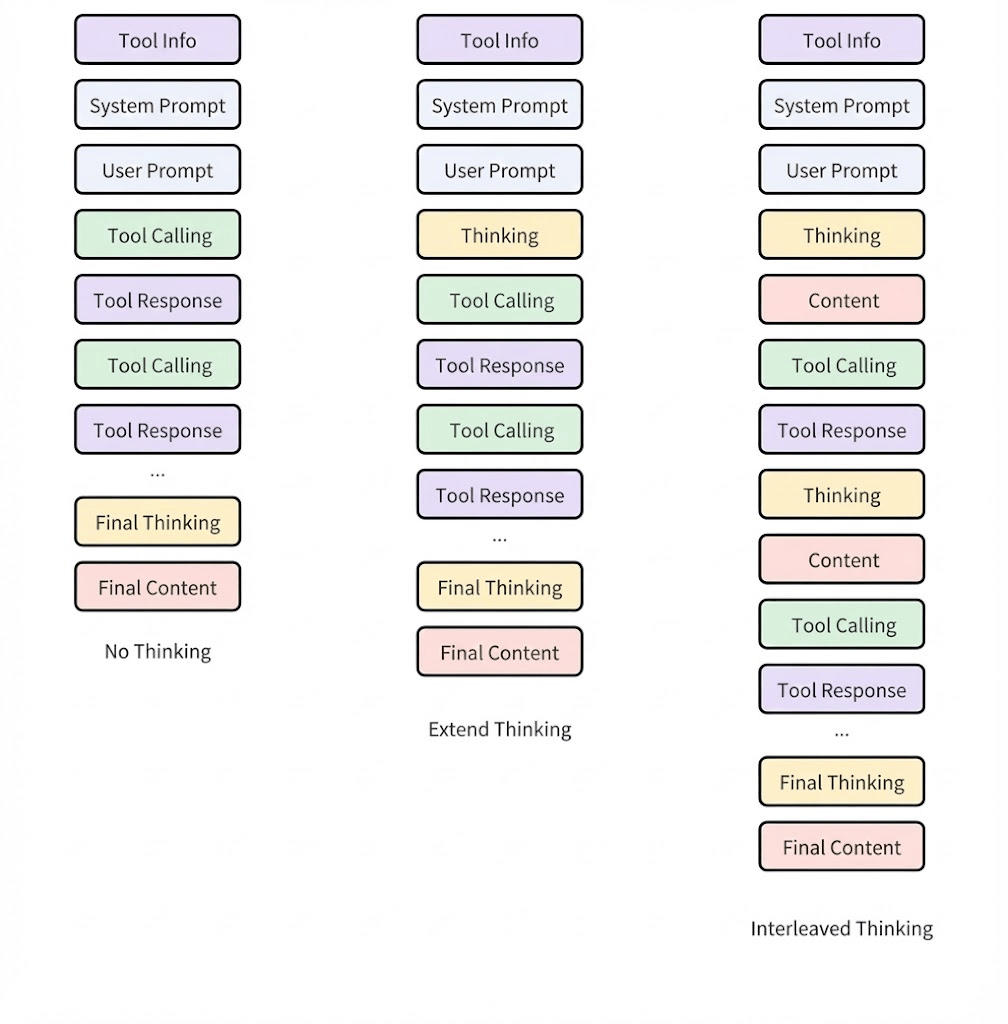
在这个闭环中,「思考」不再是可有可无的点缀,而是必须被记录下来的状态。
在每一次调用工具之前,模型必须先输出一段被包裹在reasoning_details(或类似的tag)中的自然语言。
这段文字不只是给用户看的,也是给未来的自己看的,让自己知道来时路。
为什么它能带来40%的性能暴涨?
MiniMax M2的发布数据中,有一组数据有力说明了这一机制的效果。
在常规的SWE-Bench Verified(软件工程)榜单上,开启交错思维链带来了3.3%的提升(从67.2升至69.4)。这个提升虽然不错,但还算温和。
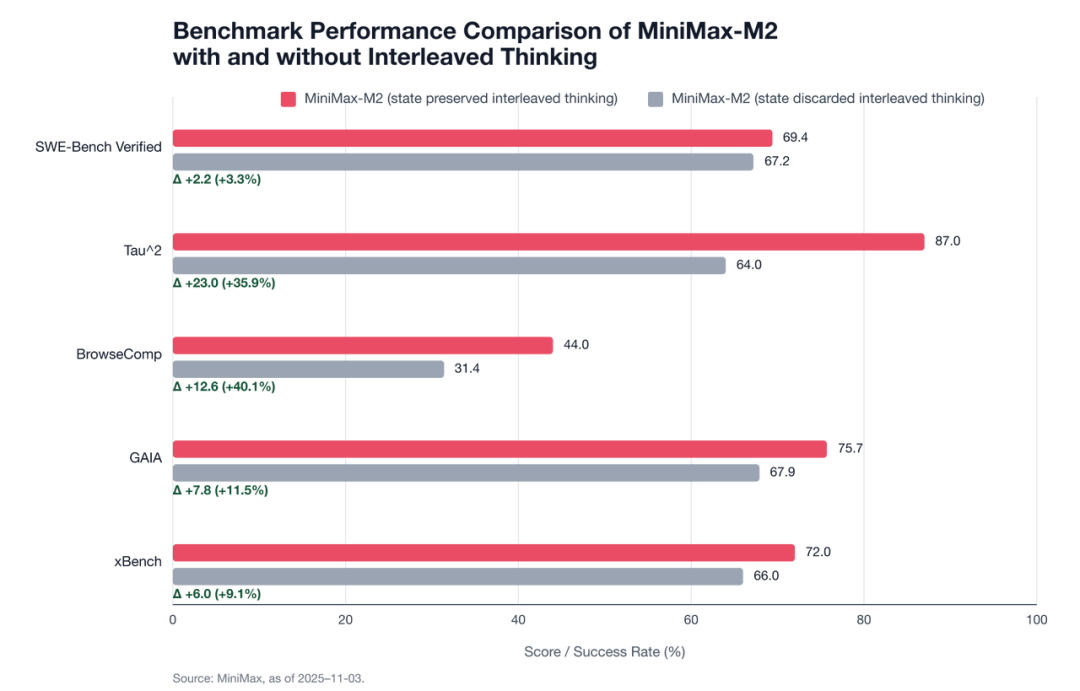
然而,在BrowseComp(网页浏览任务)上,提升幅度达到了惊人的40%(从31.4飙升至44.0);在Tau²这种复杂推理任务上,提升了36%。
为什么会有这种巨大的差异?这触及了Agent技术的深层原理。
MiniMax的后训练团队在技术复盘中指出:Agent的核心挑战,在于对抗环境的扰动。
低扰动环境(SWE-Bench):代码环境相对纯净,报错信息通常是确定性的。模型即使稍微「走神」,也能根据明确的Traceback找回逻辑。
高扰动环境(BrowseComp):真实的互联网充满了噪音。广告、无关的侧边栏、复杂的DOM结构、甚至是错误的搜索结果。在传统的ReAct模式下,模型极易被这些噪音带偏。
交错思维链实际上充当了一个「滤波器」。
模型通过显式的思考,在接收到庞杂的网页信息后,先进行一轮「信息清洗」和「逻辑校准」:「我刚才搜索了X,结果里有很多无关信息,只有第三段是我需要的,接下来我应该根据这个线索去查Y。」
这种「走一步、停下来想一步、再走下一步」的机制,极大地增强了模型的健壮性。
它将一个长达数十步的脆弱链路,拆解成了一个个稳固的「原子化」思考闭环。
泛化的本质:从「工具」到「轨迹」
Agent的泛化,究竟是在泛化什么?
早期业界普遍认为,只要让模型学会使用更多的工具(Scaling Tools),Agent就泛化了。
但MiniMax团队发现,这只是「输入层」的泛化。
真正的泛化,是对任务轨迹中所有可能扰动的适应能力。
一个模型可能在Claude Code这种脚手架里表现完美,但换到Cline或者命令行里就一塌糊涂。
因为不同的环境、不同的提示词结构、不同的工具返回格式,都会对模型的推理轨迹产生扰动。
交错思维链让模型拥有了自我修正的能力。
通过在每一步都保留推理内容,模型实际上是在不断地与环境进行「对齐」。
即使换了一个陌生的IDE环境,只要「思考-行动」的闭环还在,模型就能通过显式的逻辑推理来适应新环境,而不是依赖死记硬背的提示词模板。
这也是为什么MiniMax M2能够在xBench、GAIA等多个异构榜单上全面开花的技术根源。
MiniMax的「基建狂魔」之路
技术原理讲清楚了,但落地却是另一回事。
在M2发布之初,MiniMax面临着一个尴尬的局面:行业的基础设施严重滞后。
虽然Anthropic最早提出了Extended Thinking的概念,但由于其闭源特性,社区并未形成统一标准。
绝大多数开源工具(如LangChain、LlamaIndex)和中间件,都是基于OpenAI的Chat Completion API构建的。
而这个标准API里,根本没有地方放「思考过程」。
这就导致了一个灾难性的后果:用户在使用M2时,习惯性地把API返回的reasoning_details字段当成垃圾信息丢掉了。
模型明明在思考,但它的记忆被无意中切除了。这直接导致了模型性能的血崩。
面对这个问题,MiniMax顺理成章,开始自己着手修路。
在过去的一段时间里,MiniMax的工程师们化身开源社区的「包工头」,向全球主流的Agent开发工具和平台发起了密集的PR(Pull Request,合并请求)攻势。
Cline:这是VS Code上最火的AI编程插件之一。MiniMax团队与其紧密合作,修改了底层的消息处理逻辑,确保在IDE的对话历史中,不仅保留代码,还保留模型的思考过程。这直接让M2在Cline里的表现从「不可用」变成了「丝滑」。
Kilo Code:针对这个新兴的云端IDE,MiniMax提交了代码,优化了环境细节与工具结果的合并逻辑,解决了多轮对话中状态丢失的问题。

OpenRouter / Ollama:通过与这些模型托管平台的合作,MiniMax推动了API协议的升级,让reasoning_details字段从一个「私有协议」逐渐变成了事实上的标准扩展。
正如火如荼地进行中的AWS re:Invent 2025大会上,MiniMax也得到了亚马逊的认可。

AWS re:Invent 2025大会上,AWS CEO宣布Amazon Bedrock模型库迎来扩容,MiniMax M2作为中国模型代表在列
英雄所见略同
DeepSeek V3.2和Kimi K2 Thinking的入局
DeepSeek V3.2和Kimi K2 Thinking的发布,宣告了这条路正式成为了通往未来的主干道。

最近引发轰动的DeepSeek V3.2,其核心特性之一「Thinking in Tool-Use」(使用工具中思考),在本质上与MiniMax倡导的交错思维链是完全一致的。
DeepSeek的技术文档中明确指出:模型在调用工具时,会保持思维链的连续性,直到收到新的用户消息才会重置。
这种设计逻辑与MiniMax M2强调的「多轮交互中保留思考状态」如出一辙。
Kimi K2 Thinking也支持了交错思维链,进而得以Agentic能力上突飞猛进。

虽然两家在具体的API字段命名上可能略有不同(MiniMax使用reasoning_details,DeepSeek使用reasoning_content,Anthropic使用thinking_blocks等),但在系统设计哲学上,大家已经达成了一致:显式的、交错的、持久化的思考,是智能体进化的必经之路。
OpenAI的研究表明,AI的性能不仅遵循参数量的Scaling Law,也遵循Test-Time Compute(测试时计算)的Scaling Law。
它正在从那个只会根据提示词模板机械执行命令的「复读机」(Copilot),进化为能够在复杂的真实世界中,面对无数未知的扰动和噪音,依然能够停下来思考、自我修正、并坚定地执行长链路任务的「思想者」(Autopilot)。
而这,已成行业的共识。
参考资料:
秒追ASI